











Unser Ziel ist es, die Art und Weise, wie SIE Dokumente benutzen, um zu verstehen, wer SIE sind, und wer ANDERE sind, völlig zu verändern.
-
WER WIR SINDWir sind ein Ingenieurbüro mit dem Arbeitsgebiet TextAnalytics. Für unsere Arbeit benutzen wir technische Dokumente, um komplexe Zusammenhänge sichtbar zu machenWARUMErgebnisse werden nachvollziehbarERGÄNZUNGAls Ergänzung oder Ersatz eines Brainstormings
-
Was wir tunWir betreiben Explorative Dokumentanalyse (Mustererkennung und maschinelles Lernen), um das zu finden, was Sie sich durch klassisches Lesen sonst mühsam erarbeiten müssten.90 MillionenWerkstoffnamen finden wir ebenso wie Reaktionsgleichungen, Formeln, Herstellungsverfahren oder Normen90 Messgrößen in ca. 3000 Schreibweisen können wir erkennen und ineinander umwandeln.
-
WIR LIEFERN ANTWORTENAnstatt Experten zu befragen, die Sie zuerst suchen müssten, liefern wir Antworten aus Dokumenten, die von Experten weltweit verfasst worden sind.80 %geringerer Zeitaufwand200 %und mehr Steigerung der Ergebnissqualität
-
MASCHINELLES LESENWir haben Zugriff auf Millionen von Dokumenten mir regelmässigem Update des Datenbestands.450Millionen DokumenteUPDATESjede Woche
Numberland TextAnalyticsFactory - Wissen und Innovation durch maschinelles Lesen technischer Dokumente
Dokumentieren Sie noch, oder wissen Sie schon?
- Details
- Kategorie: Remember
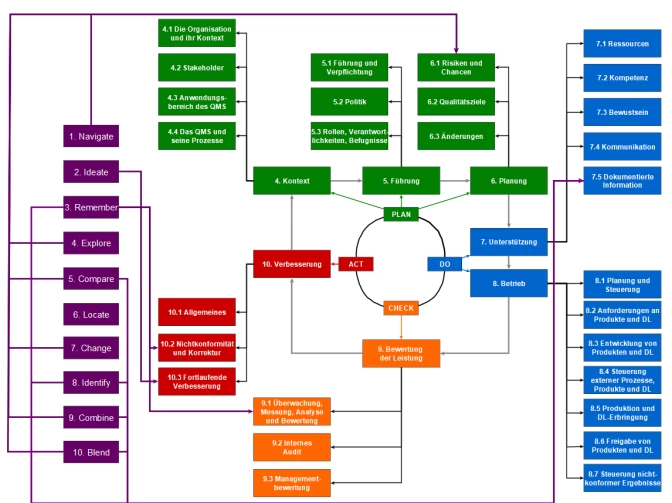
Wie Sie ihr ISO9001 Qualitätsmanagementsystem benutzen, um gleichzeitig ihr organisatorisches Wissen zu verwalten
(Eine Version der Grafik mit besserer Auflösung finden Sie hier)
Die letzte Version der Norm ISO9001 von 2015 (ISO9001:2015) hat einige entscheidende Änderungen mit sich gebracht, die Ihnen dabei helfen können, ein Qualitätsmanagementsystem nicht nur deswegen zu betreiben, weil es ihre Kunden fordern.
Zusätzlich können Sie nämlich die Möglichkeit schaffen, das Wissen ihrer Organisation so strukturiert zu erfassen und zu verwalten, dass es ihren Prozessen zugeordnet ist und zu ihren Organisationszielen passt.
Nehmen wir mal an, Sie sind ein Hersteller von keramischen Bauteilen, und eines ihrer Produkte sind keramische Gleitlager …
- Details
- Kategorie: Navigate

Wie Sie Vertriebskosten senken, indem Sie den Prozess der Neukundenakquisition optimieren ...
Wissensmanagement - Let's talk about strings
- Details
- Kategorie: Remember

(klingt irgendiwe besser als "lassen Sie uns mal über Zeichenfolgen reden", finden Sie nicht auch?)
Marktanalyse: Energiespeicher
- Details
- Kategorie: Explore

Maschinelles Lesen technischer Dokumente – oder: wie ich lernte, Energiespeicher zu verstehen
Der Ausstieg aus fossilen Energieträger wie Kohle, Öl und Gas bringt es mit sich, dass das technologische Konzept zur Energiespeicherung in Deutschland völlig neu überdacht werden muss. Energiespeichern kommt in einem künftigen Energiesystem - sei es elektrisch oder thermisch - eine Schlüsselrolle zu, da sie eine räumliche und zeitliche Anpassung zwischen Erzeugung und Verbrauch ermöglichen. Aus diesem Grund haben in den letzten Jahren zahlreiche Institutionen Machbarkeitsstudien bzw. Positionspapiere herausgegeben, in denen mögliche Lösungsszenarien beschrieben werden.